
Deepseek yang menghairankan model AI yang efektif mencabar gergasi industri. Pada mulanya disebut -sebut sebagai kos hanya $ 6 juta untuk melatih, DeepSeek V3, rangkaian saraf yang kuat, telah menjadi pesaing utama, bahkan menyebabkan titisan saham yang signifikan untuk Nvidia. Walau bagaimanapun, kos sebenar jauh lebih tinggi.
 Imej: ensigame.com
Imej: ensigame.com
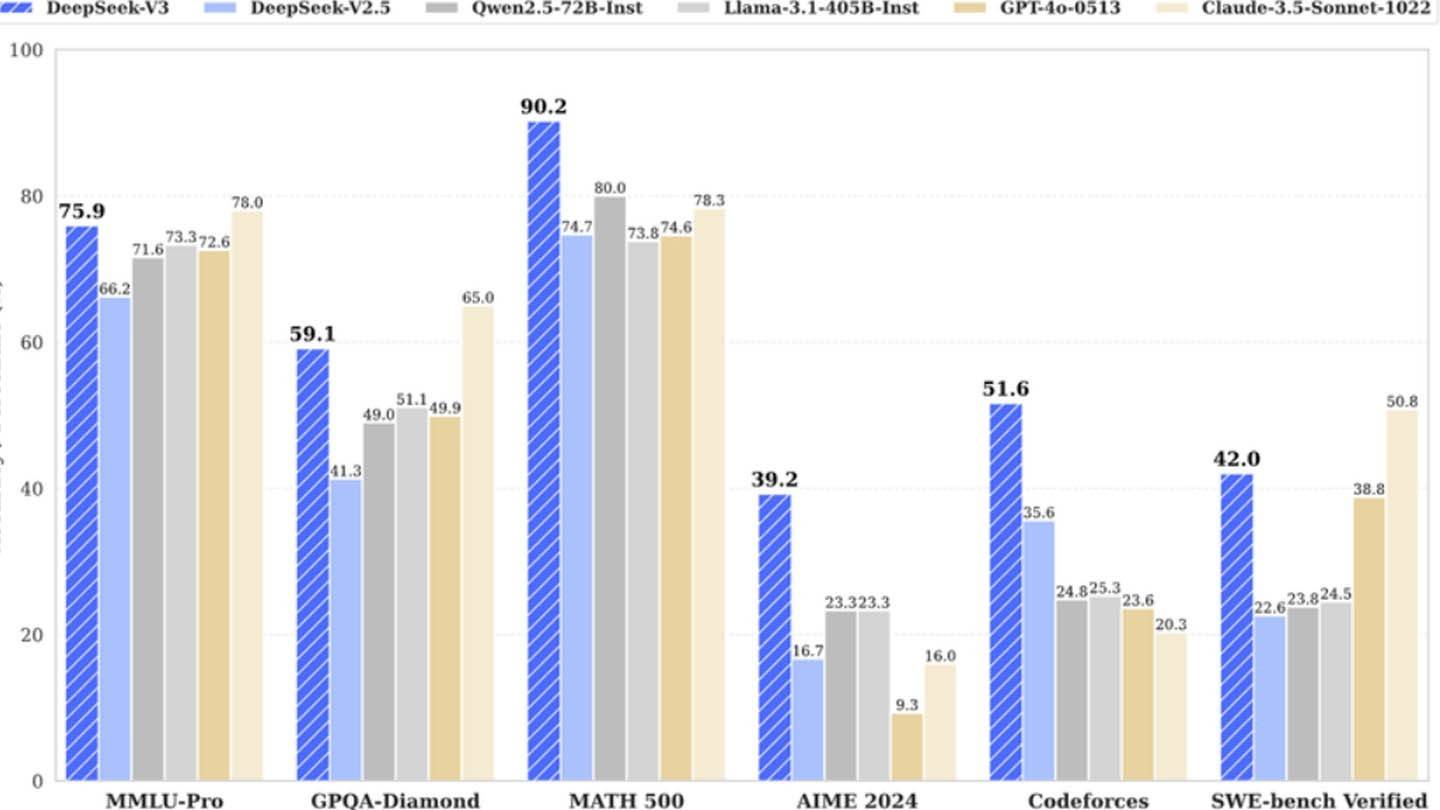
Kejayaan DeepSeek berpunca daripada gabungan teknologi inovatif: Ramalan Multi-Token (MTP) untuk ketepatan dan kecekapan yang lebih baik; Campuran pakar (MOE) menggunakan 256 rangkaian saraf untuk latihan dipercepatkan; dan perhatian laten multi-kepala (MLA) untuk pengekstrakan maklumat yang dipertingkatkan.
 Imej: ensigame.com
Imej: ensigame.com
Bertentangan dengan tuntutan awal, semianalisis mendedahkan infrastruktur besar DeepSeek: kira -kira 50,000 NVIDIA GPU, bernilai sekitar $ 1.6 bilion, dengan kos operasi mencapai $ 944 juta. Ini berbeza dengan kos pra-latihan $ 6 juta yang dipublikasikan, yang menghilangkan penyelidikan, penghalusan, pemprosesan data, dan perbelanjaan infrastruktur keseluruhan.
 Imej: ensigame.com
Imej: ensigame.com
Struktur unik DeepSeek, anak syarikat High-Flyer, dana lindung nilai Cina, membolehkan inovasi SWIFT dan membuat keputusan. Memiliki pusat datanya menyediakan kawalan sepenuhnya ke atas pengoptimuman. Pelaburan besar syarikat melebihi $ 500 juta, ditambah dengan gaji tinggi yang menarik bakat Cina atas (lebih dari $ 1.3 juta setahun untuk beberapa penyelidik), menyumbang dengan ketara kepada kelebihan daya saingnya.
 Imej: ensigame.com
Imej: ensigame.com
Walaupun naratif "mesra bajet" Deepseek boleh dikatakan melambung, kejayaannya menyoroti potensi syarikat AI bebas yang dibiayai dengan baik. Sebaliknya dalam kos latihan-DeepSeek's $ 5 juta untuk R1 berbanding $ 100 juta Chatgpt untuk 4O-menggariskan keberkesanan kos relatif DeepSeek, walaupun dengan pelaburan sebenar yang besar. Kisah kejayaan syarikat, bagaimanapun, lebih tepat dikaitkan dengan pelaburan yang signifikan, kemajuan teknologi, dan tenaga kerja yang sangat mahir.
 Muat Turun Terkini
Muat Turun Terkini
 Downlaod
Downlaod




 Berita Teratas
Berita Teratas









![Unnatural Instinct – New Version 0.6 [Merizmare]](https://imgs.34wk.com/uploads/05/1719570120667e8ec87834c.jpg)